This blog post introduces the concept of using orchestration processes to orchestrate orchestration webservice APIs with the Orchex Enterprise Orchestration Engine (EOE). Experience. Core. Template. Language fails sometimes.
Update 15.Dec.2025: After years of frustration with WordPress, I am finally abandoning this blog. The content will likely stay here for some time, but new content will appear here:
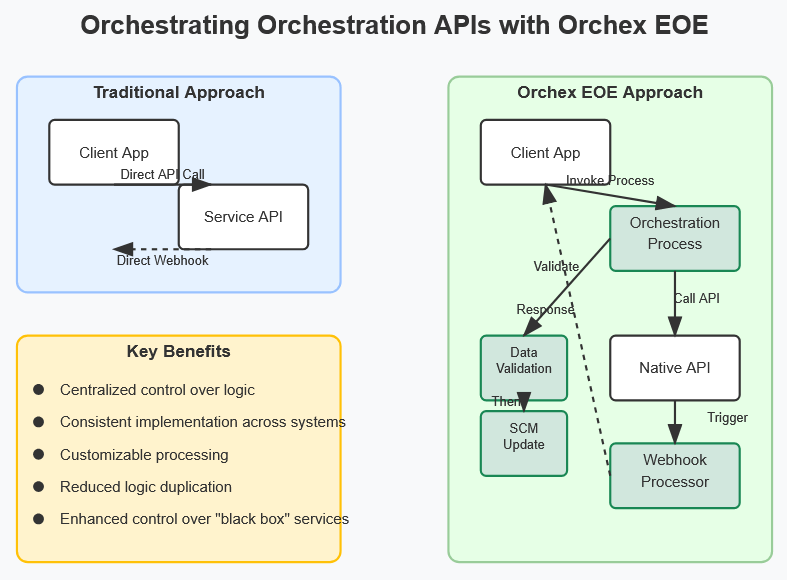
Note: I am aware that the diagram is flawed, inaccurate, incomplete, and misleading. It’s the best I could get out of Clod for free in a few minutes, and I personally can only diagram on whiteboards. Clippy 2.0 might have caught more attention, but is even less useful:
For background information about the Orchex enterprise orchestration engine, see:
One of the challenges with service-oriented applications and especially SaaS is that they function as black boxes: we can pass data to to their webservice APIs and catch their webhooks, but we cannot control the logic invoked by those webservice APIs, nor the logic that generates the webhooks.
With an enterprise orchestration engine, we can. Specifically, rather than invoking the EOE native webservice APIs, we can implement orchestration processes that wrap those APIs. And instead of raising webhooks, the EOE can invoke orchestration processes that can be functionally equivalent, but that we can tailor with orchestration processors.
For example, when we want to define a processor in the EOE, we may want to perform some data validation or other logic, such as to update a source code management system with that content. With a traditional service-oriented application, we might implement the required logic in the calling code, which would validate the data and/or call the webservice APIs required to update the source code management system and otherwise. If we have different systems that do the same things, we need to implement the same logic in each of those systems.
Rather than invoking EOE native webservice APIs, we can implement an orchestration processor that calls the native webservice API, and add additional processors to implement an orchestration process that performs the desired functionality. We can do the same thing around webhooks – rather than the EOE generating the HTTP request to a webhook listener directly, the EOE can invoke an orchestration processor that defines functionality equivalent to what a direct webhook would otherwise do.
It would still be possible for clients and applications to invoke the EOE native APIs without orchestration, but going a step further, what if the EOE does not even expose such APIs? And what if, instead of using its own APIs directly, the EOE *always* invokes such orchestration processes that in turn invoke its native webservice APIs, and always invokes orchestration processes with processors equivalent to webhooks? Then we would have consistent, centralized control over all significant logic in the application, with the ability to customize almost anything to suit our purposes.
Currently, partly for simplicity (it’s complicated enough already) but also to reduce resource utilization and optimize performance (and because we don’t believe in microservice architecture), Orchex uses its own Rust APIs rather than using its webservice APIs. This could change, or flags or other techniques could control this functionality at the environment, project, customer, instance, or other level within the application.
Orchex will almost certainly take this approach. Luckily, we also believe that applications should have very few webservice APIs, preferring orchestration over direct webservice API access.
